While preparing for a monthly Lunch-and-Learn lesson for a client, I wanted to collect various examples of good, bad, faulty, and missing HTTP response headers. As is typical, I went a little overboard and collected all of the headers for the top one million websites. This article will describe some interesting findings and the raw data collected, as well as provide other researchers with the script created and used.
The Script
The script is a simple multi-threaded python script that can easily collect the headers for one million websites in 24-48 hours, depending on your bandwidth and the number of threads used.
Script Source: https://gitlab.com/J35u5633k/httpheaders_public
As is typical for our first-release version, there is almost no error checking or optimization. It got the job done that we needed it to do. Feel free to modify as needed – remove the allow_redirects, change the output format, etc.
In addition to the script, you will need a list of domains. I used: https://github.com/PeterDaveHello/top-1m-domains?tab=readme-ov-file
The Raw Data
The raw data from the top one million websites can be found here: https://drive.google.com/drive/folders/1gL0xTnN-12aXnPM4B0F4Mir7yXmSPk1-?usp=sharing
Before releasing the raw data, I made a few modifications:
- removed all “Set-Cookie” values and replaced with 12-A’s
- anonymized IPs, GEO coordinates, city names, etc.
If you need access to the data that was removed or anonymized, you will need to run the supplied script for yourself.
Interesting Findings
Most commonly seen headers

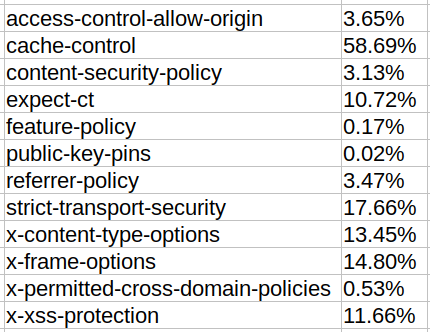
Usage of common security headers

Leaked private/internal IPs

Internal Hostnames


Sites with the most headers

Header values with one character per header
Some of the sites with 40+ headers have a misconfiguration causing a single character to be sent per line.

Debug Headers
Other sites with 40+ headers were due to debug headers.



Conclusion
If you would like PEN Consultants to provide your team with monthly training, or if you would like to discuss any of our testing services, we would love to speak with you. Contact us today!
If you are looking for a reliable and experienced offensive security service that provides Rock Solid Security, look no further than PEN Consultants for all your information and cybersecurity testing needs. Contact us: https://penconsultants.com/contact-us/